
Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.
Dataset
This Q&A dataset is based on thirteen scenes part of the Replica dataset: six multi-room scenes -
a 2-floor house (apartment 0), two multi-room apartments (apartment 1, 2, hotel 0), two different
setups of the FRL apartment (FRL apartment 0, 1); and seven single-room scenes - three apartment
rooms (room 0, 1, 2), and four office rooms (office 0, 2, 3,
4). We manually constructed 1000 questions with answers: 100 for all multi-room scenes, 60 for
apartment rooms and two offices, and 50 for the remaining two offices. The answers may have one of the two
forms: ground truth information for factual data, such as the number of objects in a room, or an
illustrative image of the objects/rooms of interest for questions that involve descriptions or identifying
similarities. This distinction allows to not penalize the answering system's creativity. The questions
were divided into 6 categories, adjusted for indoor spaces from the spatial
taxonomy for GIS applications: object location, measurements, pattern identification, navigation,
spatial relationships, and predictions.
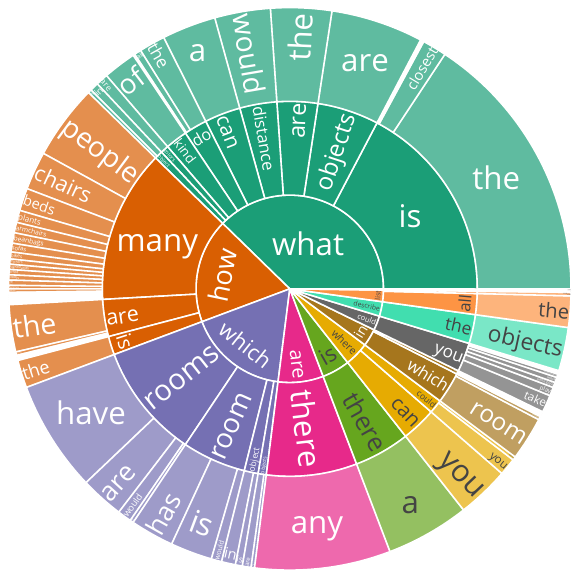
a) Question distribution based on their first three words
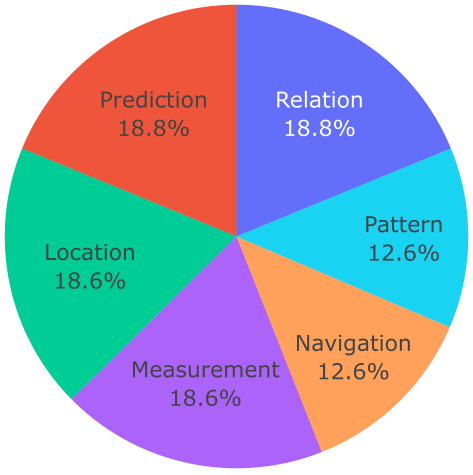
b) Question distribution based on their categories
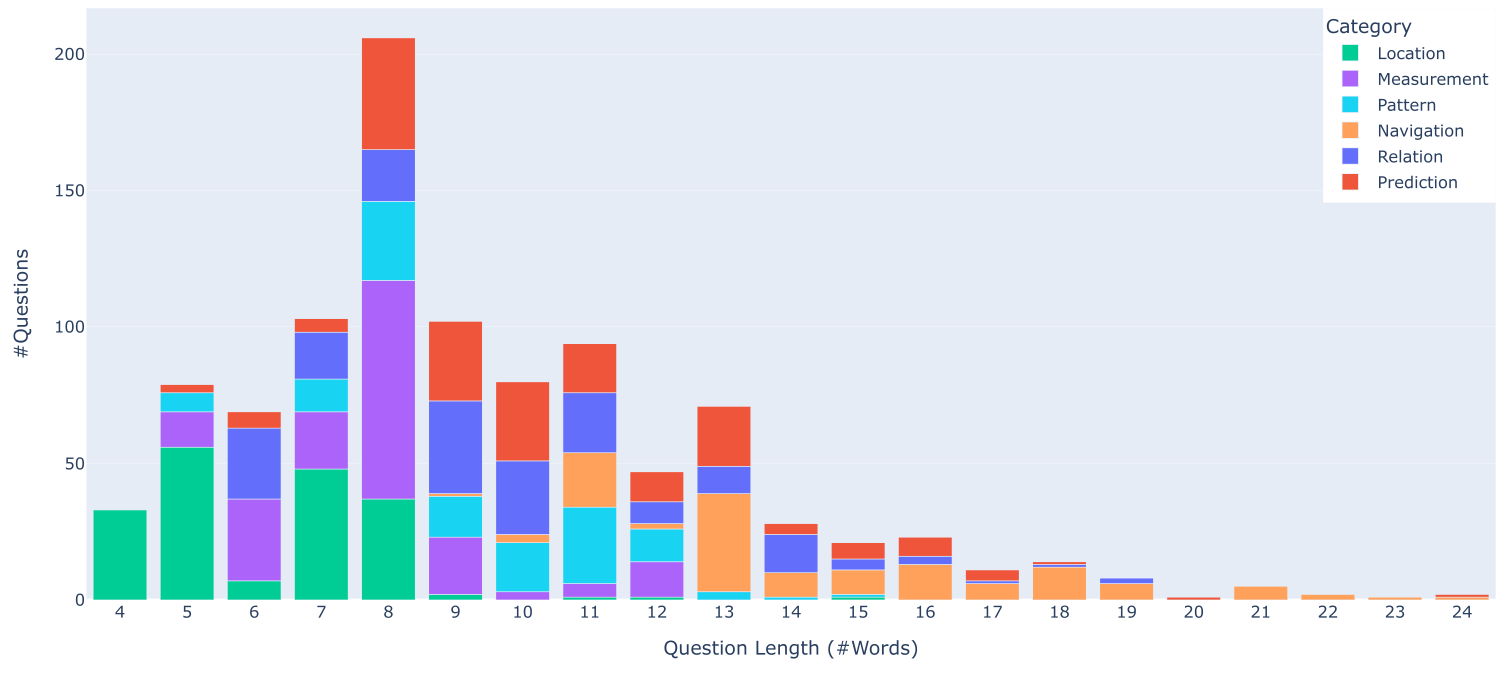
c) Question distribution based on their lengths
Statistics of questions in the dataset. The dataset has a large variety of phrasings (a) and is well distributed across the question categories (b). Furthermore, the questions are overall concise with an average length of around 8 words, but some longer ones are also present (c).
Automatic assessment
The goal of the automatic assessment is to evaluate the responses from an answering system with respect to the
actual state of the corresponding scene in the dataset. We divided the assessment into two cases: Ground
Truth Check - when the ground truth is indisputable (e.g. number of objects in the room), Answer
Cross-check - when the definition of the ground truth would either need to exceed context length or
would unnecessarily limit the answering system's creativity (e.g. finding similarities between rooms). In both
scenarios, an LLM is provided with the question, the system's answer, and the acceptance criterion, which
varies based on the question type. In the case of the Ground Truth Check, the message to the LLM is
extended with information on the actual state of the scene with respect to the given question. Answer
Cross-check, however, provides an image presenting the corresponding scene(s) in question, accompanied
by an example answer. This way, a VLM can decide whether the actual system's answer matches the reality, and
not necessarily matching the example, reducing the bias of the assessment system.

Automatic assessment procedure. The left chart presents the scenario of Ground Truth Check, the right one depicts Answer Cross-Check, used respectively for indisputable data and more creative answers.
To generate answers for the assessment system to evaluate, we propose RAG3D-Chat, a spatial Q&A system based on two main components: Semantic Kernel (SK) and Retrieval Augmented Generation (RAG) within Llama Index framework. Semantic Kernel, being an open-source framework for LLM-based implementation of agents, allowed for integrating four complementary modules - each with different applications and limitations - into one system. Once the modules were implemented and described with a corresponding prompt, Semantic Kernel's planner was able to propose a chain of function calls, whose result would be an answer to the input question.
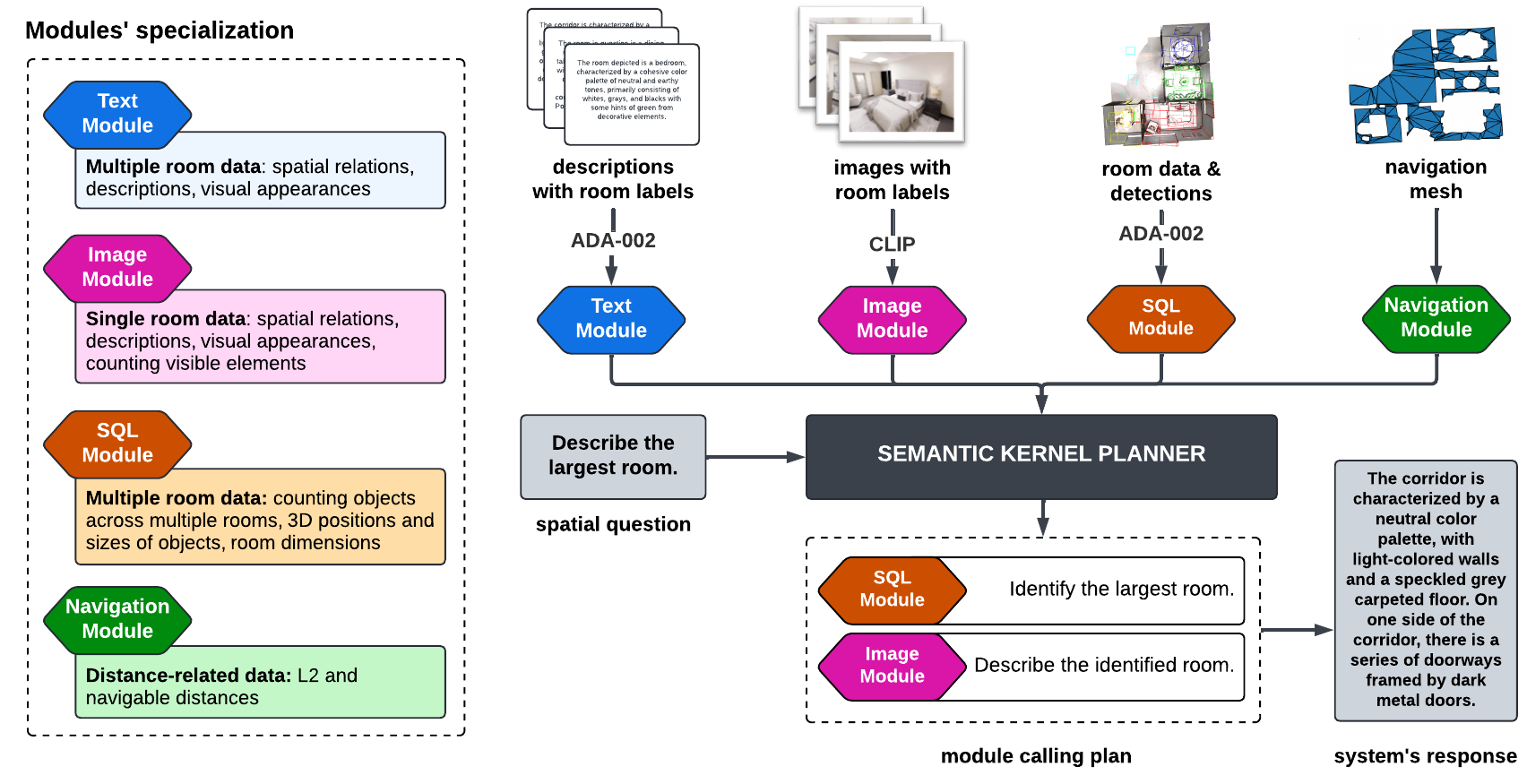
Overview of RAG3D-Chat. Based on the received question, the Semantic Kernel library orchestrates the calls of four different modules having different specializations and types of input.
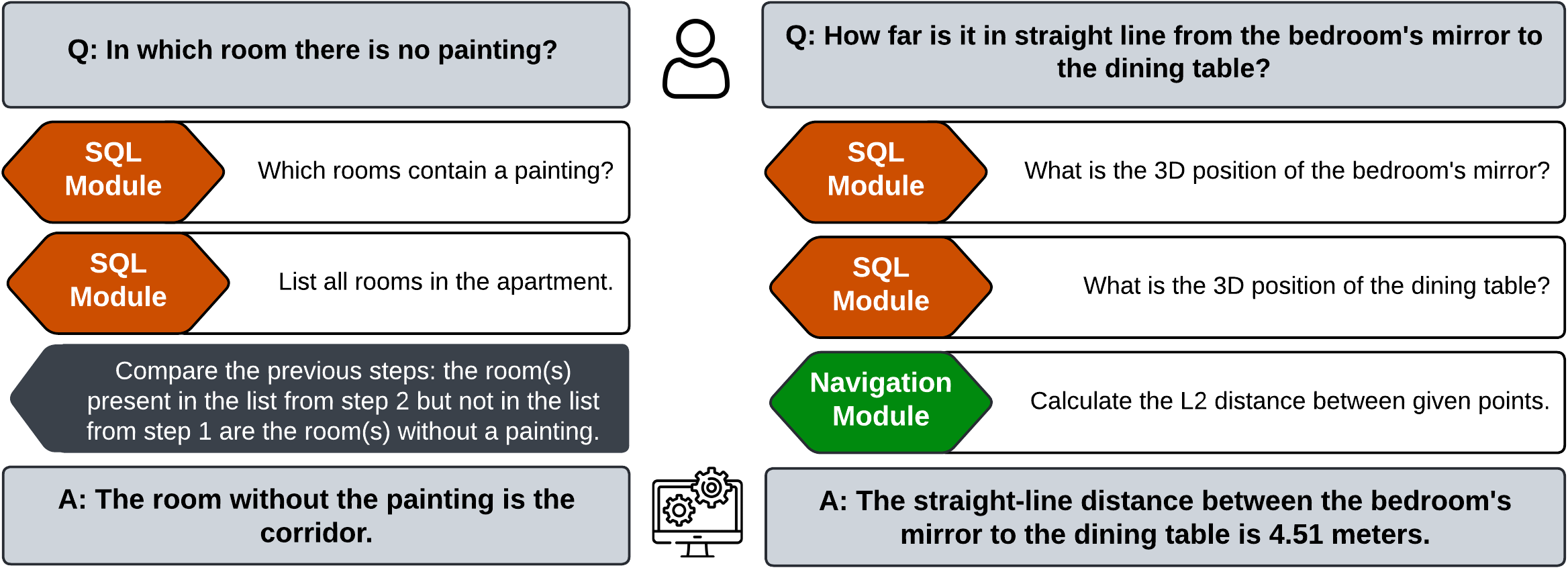
Example of modules chained together by the planner. Semantic Kernel's planner divides the user question into subtasks and calls the modules in a sequence to finally formulate a response based on the retrieved information.
Evaluation of the Automatic Assessment
To ensure that the automatic assessment correctly accepts or rejects the answers, we conducted a user
study. We exposed 60 people to a random sample of 40 questions drawn from a 100-questions scene, asking
them to assess the correctness of the system's answers. Additionally, 10 abstracted questions were added
to get an insight on people's reasoning in case of ambiguous answers. The automatic assessment agreed with
the majority of participants' responses in 39 out of 40 cases, reaching the absolute agreement rate of
97.5%. The detailed results of the user study can be found in a separate
webpage.

Results of the user study. The chart presents the agreement of the participants of the survey with the system. The users agree with the answering system agrees on 97.5% of cases, with a weighted agreement score of 86.4%.
Baseline Results
RAG3D-Chat achieves an accuracy of 66.8% on the 1000 questions of the proposed dataset. The system correctly
addresses most of the questions in each category. Predictions pose the biggest challenge for the system,
accounting for 76 failed cases.
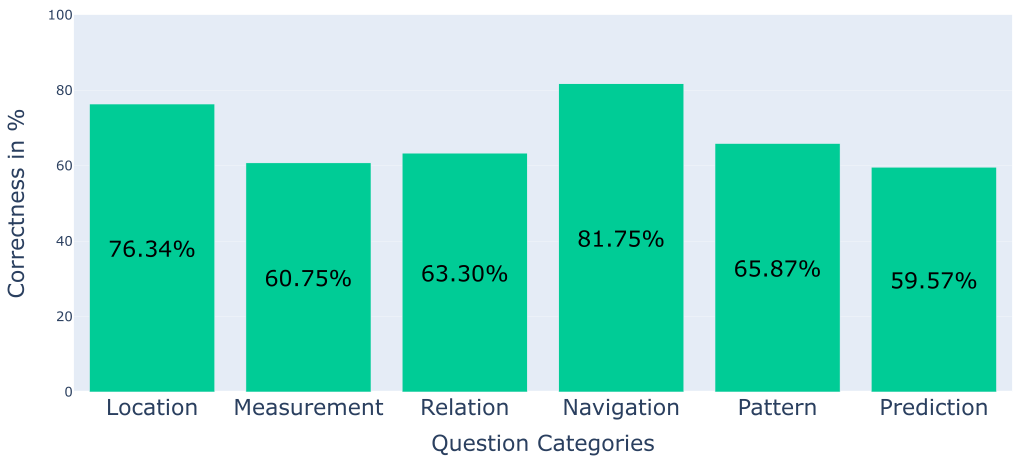
Results of the baseline on each category of questions. Although the highest percentage of correct answers belongs to navigation-related questions, it is the location category with the highest number of correct responses because of the larger number of questions in this group.
@inproceedings{szymanska2024space3dbench,
title={{Space3D-Bench: Spatial 3D Question Answering Benchmark}},
author={Szymanska, Emilia and Dusmanu, Mihai and Buurlage, Jan-Willem and Rad, Mahdi and Pollefeys, Marc},
booktitle={European Conference on Computer Vision (ECCV) Workshops},
year={2024}
}